What machine learning methods would you use under the following conditions?
- Binary classification problem, supervised learning
- One or more continuous features, such as term frequencies
- Label A will most likely have a score between two values. Any lower may suggest label B, but any higher may suggest label B as well
- The optimum range for A is not known but could be learned from the training data
It doesn’t seem like logistic regression would work here because it models cases where every increase in a feature’s score makes the likelihood of category A or B greater, and it finds the features that best fit this pattern. What approach would you considering for this type of problem, and what factors would be most important to your decision? Are there domains where this kind of problem is often worked on? (Maybe authorship attribution in cases where the categories are “same author” and “some other author”?) Thank you for any thoughts you might have.
Hi there! If you say that label A can have a score between two values, doesn’t that mean it’s not a binary classification problem after all? I’m probably missing something. 
Hi @folgert, I’m describing a situation where a feature’s value is, say, between 1 and 100. That feature could help predict a label (say, A or B) but cases belonging to label A tend to have a value between, say, 20 and 30, whereas values of 1-20 and 30-100 suggest label B. In other words, it’s a binary classification task, but the relationship between the feature (or features) and the labels isn’t linear.
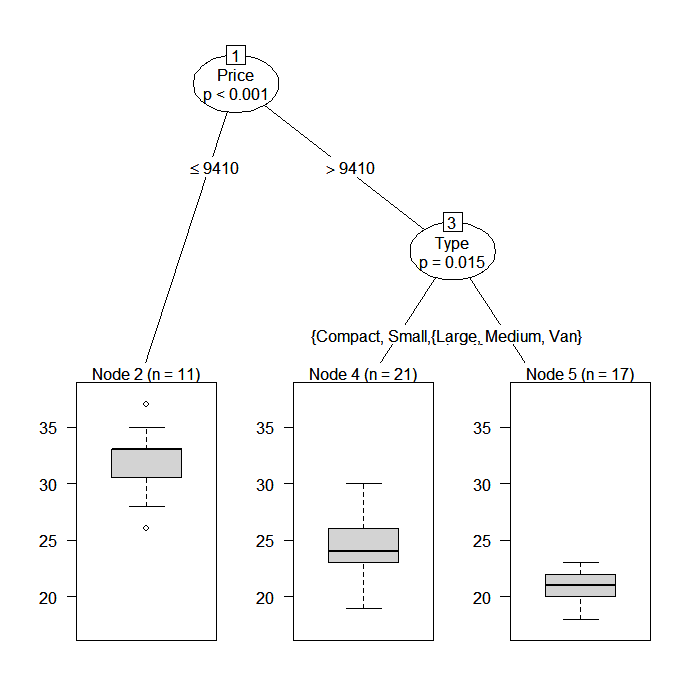
I see! If you don’t mind applying a black box, SVMs could be of use in such situations. A more intelligible model would be a simple nearest neighbor classifier. See for example the k-NN implementation in TiMBL. Or, similarly flexible, very informative but a bit slow in high-dimensional spaces, Conditional Inference Trees. The R implementation provides these nice looking graphs:
1 Like
Is there a reason why the lower end Bs and the higher end Bs are both Bs? If the problem would be re-cast as a ternary classification problem (A, B, C), multinominal logistic regression would again be applicable (and C items could be re-labelled as B in a postprocessing step).
SVMs work in such cases because they use the “kernel trick” which first transforms the features into another space (eg, x^2) and then applies linear classification. If you know what your features are like you can of course also try to first apply a “kernel” (ie transform your features in some way) and then apply a linear classification like logistic regression. In your example, if you don’t take feature x directly but instead (or in addition) use (x-25)^2 or another similar transformation, then you can apply a linear classification to this. Another option is to add another feature (split feature x into two features) so it can be separated linearly.
4 Likes
Thanks for all these replies!