I have a complicated corpus on which I would like to perform some measurement like a similarity metric of texts amongst each other. Fuzzy reuse detection or intertextuality detection would also be ok.
However, the corpus is complicated in the following way:
It’s a recipe group of one alchemical recipe which is the content of every text, yet the recipe changes with experimentation. First we thought it might be a special form of a stemma, yet we have realized in the meantime that it is not. However, it’s also not helpful to detect topics or use topic-related measurements because the texts are extremely similar overall. They also have different lenghts (from half a page to 20 pages), so some thematic variation can easily happen due to differences in text length - even when the chemical message of the text isn’t very different.
The texts are mostly in early modern German (Frühneuhochdeutsch), so many out-of-the-box methods don’t apply.
We have already used a few things but the results weren’t extremely helpful. We have also tried semantic tagging which was helpful, yet we also encountered a visualization problem: We need to compare 30 texts to each other and it’s getting really hard to create a useful output. If it were one stemma we can relate all other texts to, it would be easy but sadly it isn’t.
We have tried exact string matching (using longest common subsequences) which has yielded not so bad results because many texts use direct quotations from other ones to which they relate.
We have chosen this approach free of normalization and common NLP pipelines because we initially thought that spelling variants might be indicative of relationsships between the texts (only very few can be dated properly), so we didn’t want to “normalize them away”. But after further consideration, I feel that we might have overestimated the value of these orthographic differences, so I’m thinking about maybe normalizing them, so that we’d have more pre-existing tools/libraries accessible to us.
(Also, maybe relevant to know, it’s a non-funded side project, so I don’t have lots of resources, either time or money, so I’m not sure if I can do the normalization at all, even though the corpus isn’t huge).
What would you say my task is? I’m unsure whether what I want to do is really intertextuality detection, a similarity metric or text reuse detection…
I’d be happy to hear some of your suggestions and thanks for reading this long post
Best,
Sarah
PS: I already saw this post Spelling variation in historical language where people suggested FastText which I haven’t tried yet - I sure will try but I’m somehow doubtful it would give useful results on a corpus like mine even if they offered the language in question… what do you think?
Specific techniques for discovering text re-use is not my specialty but perhaps people like @enrique.manjavacas or @mike.kestemont can help here.
The task as you describe it reminds me of phylogenetic approaches to textual change. If you frame it like that, you may want to consider using multiple text re-use measures, rather than a single one. This would mean you create some feature vector of text-reuse metrics and perform your analysis on that. You could then also consider assigning different weights to the different features, to make sure the value of certain aspects (like orthography) are not overestimated.
I’d be interested in what other people have to say! Thanks for the question.
You might want to consider lemmatizing your text. Since you’ll be having to deal with spelling variation but probably would like to do matching on terms abstracting over morphological differences, lemmatization might solve both issues at the same time. Also, even if a lemmatizer gets the actual lemmas wrong for particular word types, that’s not so bad as long as the errors are consistent. Now the self-plug. We did some work on lemmatization of historical languages (https://www.aclweb.org/anthology/N19-1153/) and did some experiments on historical German using the REN corpus. I think you could find enough training material for a decent early modern high german lemmatizer. If you are interested I could train a specific model for your corpora, or help you tagging it.
I am also working on a python library for text reuse detection, there are 3 types of algorithms (using set-based metrics, alignments and vector space models) and we are looking into improving coverage through the integration of distributional semantics. That’s unfortunately still ongoing work, but if you are interested the repository is here (not very well documented at the moment): https://www.github.com/emanjavacas/retrieve
If the texts are not overly long, it might be useful to run the parallel versions through https://collatex.net/ which is good at aligning parallel witnesses. (If you run the algorithm at the character-level it might even solve some of the orthographic variation.) Running FastText would be cool too, but is unlikely to be successful if there is no sizeable reference corpus available of Frühneuhochdeutsch. (Is there?)
I would also try to avoid a full NLP pipeline if you don’t need it. If there’s no lemmatizer available for this kind of material, it would take you ages to create one (which doesn’t feasible for a side project).
thanks so much for answering my question / contributing and sorry for taking ages to write back.
In the meantime, I have decided that I will write a grant proposal for a small grant to get this work done (and also be able to try all the methods and evalute the effectiveness etc) because a grant scheme came up which might make this possible.
I will take all your ideas into account - they were very valuable. I’ll also have to write up my first paper on this at the end of the month - so I might be back with some questions then
It would be really fun if we got the money and I had the time to test out all the great suggestions you had…
(also, given that we are applying for more money, in case you had thus far held back on some additional ideas because you thought they’d be too time-consuming - I might actually have time for this next year if the project goes through…)
I have already tried collatex and comparable tools (juxtacommons or Uni Halle’s LERA tool), however, these tools are meant for very similar texts which actually form a stemma. Mine are very stimilar but they don’t really form a stemma because people have been adding their own experimentations and experiences, thus changing the text too much to be a stemma. Also, these tools obviously would get small orthographical differences but in reality, they don’t because the overall text is too dissimilar.
This realization that tools like Collatex don’t work for me actually was my starting point.
What I did, essentially was exact string matching (using Python, writing it back into TEI-XML) - which worked surprisingly well - and visualizing them in a custom LaTeX transformation (the owners of the data are a bit old-fashioned and got scared with HTML so I decided I’d better make PDFs for them).
I will definitely consider multiple text reuse metrics, like @folgert said and I will also give @enrique.manjavacas’s lemmatization a shot which sounds fascinating! Maybe will also try fasttext… @folgert Do you have any literature tips on phylogenetic approaches to textual change?
Oh and @mike.kestemont: I had also thought about using some plagiarism checker. I’ve been fascinated about that topic for a while (using the web to find intertextuality in my early modern texts) in a way that doesn’t crash the internet or gets me blocked :D) but I haven’t really made any progress yet. Also, of course, this will only capture texts which have been digitized and transcribed/OCR’d which is pretty biased after all… I’ll also look into this again should I get the money.
However, since I will be writing a grant proposal for this now, there won’t be any actual progress any time soon as my time will go into writing the proposal
Thanks clarifying this, @sarah.lang! I understand the background of the problem better now. I’ve worked with Tracer before and always found it a bit daunting because it has so many settings and can be hard to parametrize, especially if you’re not deep into the (Java) code. In my own research or tutorials (much simpler problems!) I often resort to this more straightforward (Python) library for spotting text reuse: https://github.com/JonathanReeve/text-matcher.
thanks for the link - and also for admitting that you find Tracer daunting too. I have felt the same way - it’s kind of scary and I didn’t get the hang of it. And since I wasn’t sure it was going to be a great match/solution for my problem anyway, I decided to not pursue it any longer.
Maybe should I get the project, I might try again…
Hey, sorry for the late reply. The literature on all of these is way too broad to specify any particular paper. I am currently working on a survey that I hope to put out soon that is quite related. I will post it here once it’s out.
The work of Sara Graça da Silva and Jamie Tehrani comes to mind. They are not using automatically extracted features, but the setup could be quite similar. Here are two papers:
Hi Sarah,
I just finished a project where I had to detect text reuse on a very messy Twitter corpus. I tried Tracer without success and then moved to Passim and BLAST.
Out of 14k tweets, passim identified only 500 text reuses (4%), BLAST 7k (52%) with very few false positive.
BLAST is a bioinformatics tool but you can substitute proteins with letters and find matches in text instead of DNA sequences. Only downside is that it cannot match paraphrases like Tracer is supposed to do.
in the meantime - it was already ages ago that I last wrote! - we have completed the first part of the grant application. Let’s hope that they invite us to write the full proposal and then take the project because it would be a really cool one…
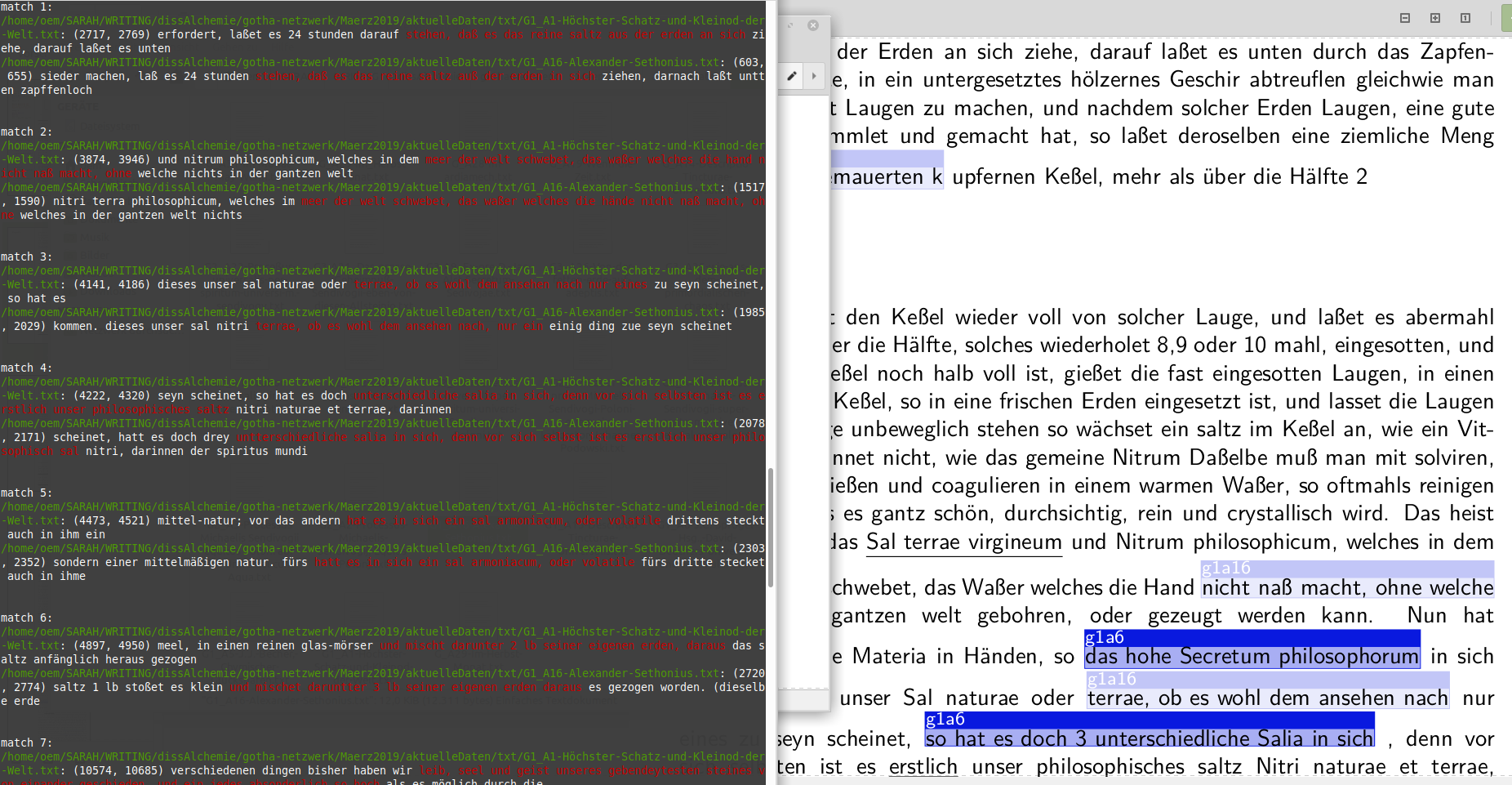
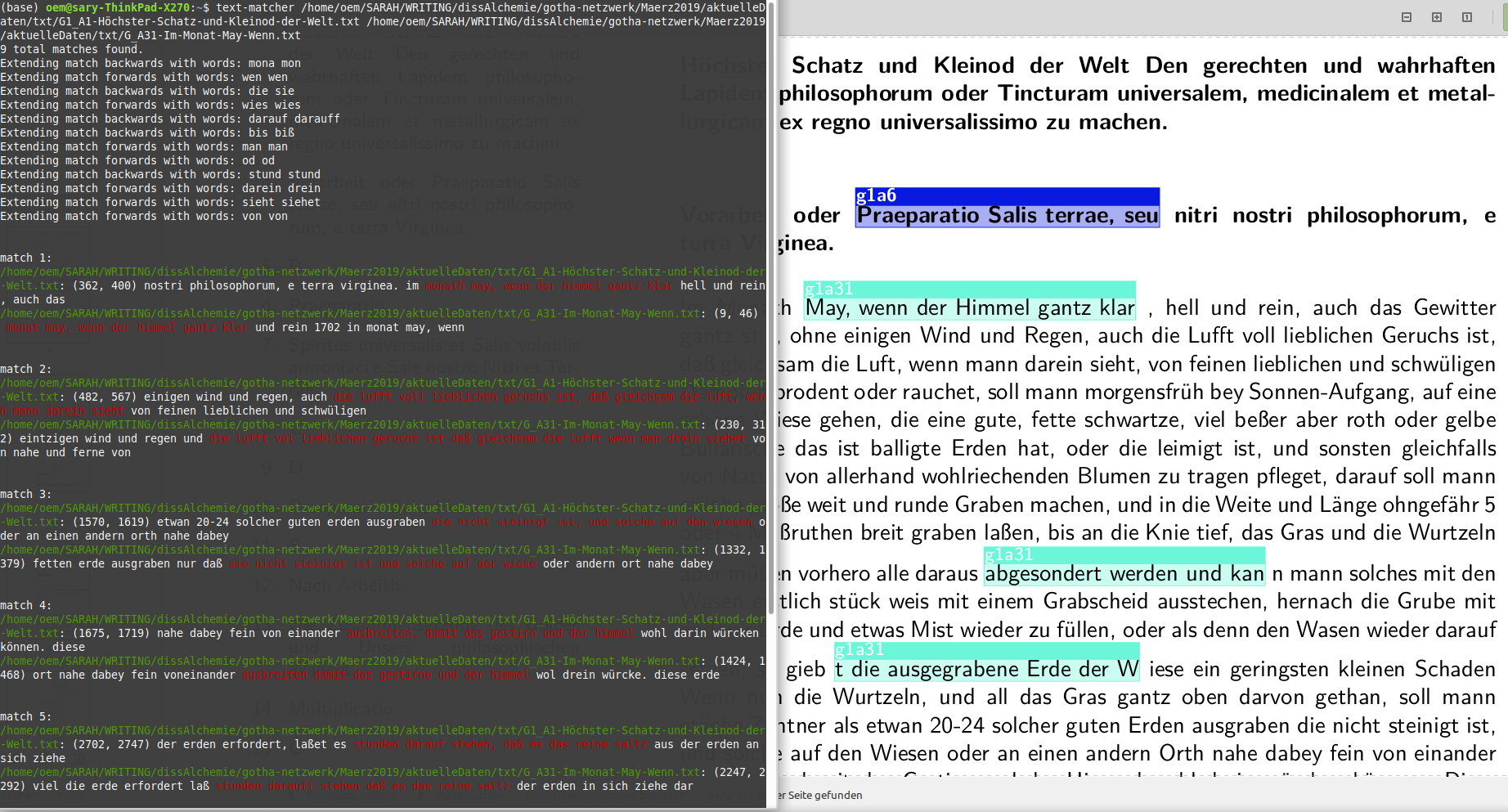
Anyways, I’ve tried the text-matcher and it was really good - especially as it basically did what I was doing anyway (but of course, my short code didn’t do it as well). Thanks a lot for that.
The problem with that is now that I’d need to write those results back into my data and we’re currently speaking between 40-50 texts which all need to be compared against eachother, so really not something I can manage as a side project.
Anyways, I wanted to share some screenshots of the textmatcher (CLI output) compared to my old analyses (in the meantime 1,5 years old) which were visualized in LaTeX and which had missed out on some very obvious textual overlaps - that text-matcher got.
In this image, you can see one of our nice results: The paragraph at the right hand side doesn’t show any matches (of course, it’s easily possible they were not found by accident or we didn’t include the corresponding intertext in the corpus). But if it were actually free of intertext, it could mean that this text came from the author’s own experimentation.
Can I ask - what is the effect of having lots of hapaxes in the text (from not normalizing, thus not lemmatizing etc) on algorithms like stylometry? Does it behave much worse? Because my results seem ok - but just wondering.
It was 70% hapaxes, is that normal according to your experience? My values are:
Total number of types in corpus: 4907
Total number of hapax legomena: 3578
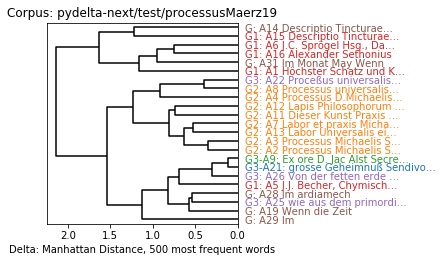
As you can see - the human-chosen groupings are denoted with “G1”, “G2” and “G3” and they are recreated pretty well by the (pydelta) stylometric analysis.
Thanks again for your help!
Hoping you’re all well,
Sarah
If I understand everything correctly, the hapaxes have no influence on the analysis because you only used the 500 most frequent words to calculate the Delta distance.