Hi all! Does anyone know about a study which compared clustering algorithms for texts, images or other data from the humanities? Many clustering algorithms work well with specific forms of cluster (kmeans presupposes a ball like structure, dbscan works best if there is a clear boundary between dense areas and the surrounding areas) and in my experience with texts my data seems to be exactly the opposite, strange forms and rather messy, but this is more or less anecdotal. So what is your experience and do you know whether someone did a study on this subject? Thanks in advance! Fotis
2 Likes
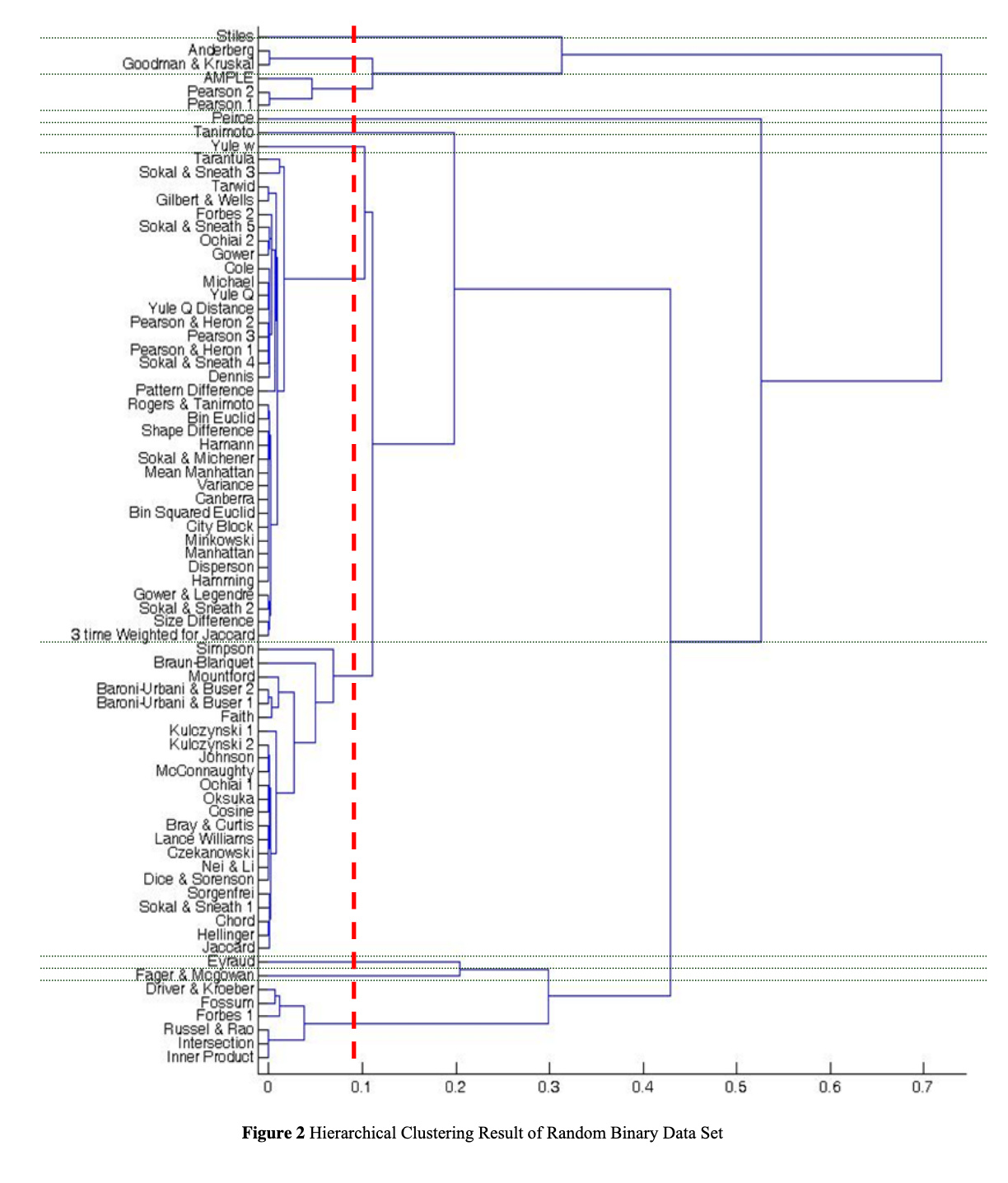
Hi! I’m not aware of a survey of clustering algorithms applied to text, and would also be interested in one! Bit related: I do know about this nice overview of Binary Similarity and Distance Measures, which aims to show how different distance metrics cluster together. Perhaps a similar approach would be useful for you.
1 Like
thanks, that overview is really interesting. They are using a random data set to make the similarities visible. To find the best clustering algorithms for text, we would need a text corpus where we know all aspects which could influence the clustering (author, period, genre, theme, proportion of direct speech etc.), ideally because we generated it 
1 Like
Hi Fotis,
I think the choice of clustering algorithm largely depends on how much you know about your data and how well you can optimize your hyperparameters. In our SemEval Paper on diachronic sense change, we found that GMMs (Gaussian Mixture Models) and HDBSCAN (Hierarchical DBSCAN) performed best and were practical (while DBSCAN and BIRCH had some issues). An issue of GMMs (and k-means) is that you need to know the number of clusters in advance, while HDBSCAN had issues with high dimensional data (768 dimensions from BERT was too large). For all our setups it really helped to have some evaluation data to tune our hyperparameters, consequently improving the results.
From the top of my head, I do not know of any clustering evaluations for text. I’m assuming you are particularly interested in text that is embedded through contextual embeddings? You might find some older work on topic models and clustering for sure.
Sklearn has a nice overview of different shapes in data and how well clustering algorithms handle that:
https://scikit-learn.org/stable/modules/clustering.html
I’d be very interested in using clustering approaches to determine literature periods from poems. I have period annotation for 158 German poems.
2 Likes
a systematic study of [method x] is generally exactly what we still need!!
slightly relevant paper comparing “distance” metrics with respect to ground truth labels for authors. Maybe a useful model.
DOI: 10.1093/llc/fqy013
and there was a piece comparing classification algorithms based on text ground truth:
DOI: 10.1093/llc/fqn015
and there will be a new piece coming out in CA this summer that argues that “distance” is not a useful way to think about textual similarity (it’s deliberately polemical and I hope people will engage with its premises).
3 Likes
There is a recent one by Krakow stylometry team:
Bottomline: “Ward’s linkage outperformed other algorithms” in authorship attribution task
2 Likes