- Computational analysis of artistic style prevalence in generative AI art (Thomas Efer and Andreas Niekler)
- The Evolution of News Headlines (Pietro L. Nickl)
- Evaluating State-of-the-Art Handwritten Text Recognition (HTR) Engines with Large Language Models (LLMs) for Historical Document Digitisation (Christel Annemieke Romein, Achim Rabus, Gundram Leifert, Tobias Hodel and Phillip Ströbel)
- The Flemish Operation: Language Choices in the Repertoire of the Antwerp Opera (1893 – 1934) (Mona Allaert and Mike Kestemont)
- Metronome: tracing variation in poetic meters via local sequence alignment (Benjamin Nagy, Artjoms Šeļa, Mirella De Sisto, Wouter Haverals and Petr Plecháč)
- Analysing Image Similarity Recommendations Across Photographic Collections (Taylor Arnold and Lauren Tilton)
- Understanding the Role of Speech Acts in a Large Corpus of Political Communication (Klaus Schmidt, Andreas Niekler and Manuel Burghardt)
- Mining the Dutch attitudes towards animals and plants (Arjan van Dalfsen)
- Towards emotion analysis for Alsatian theater (Qinyue Liu, Pablo Ruiz Fabo and Delphine Bernhard)
- Large language models to supercharge humanities research - Andres Karjus
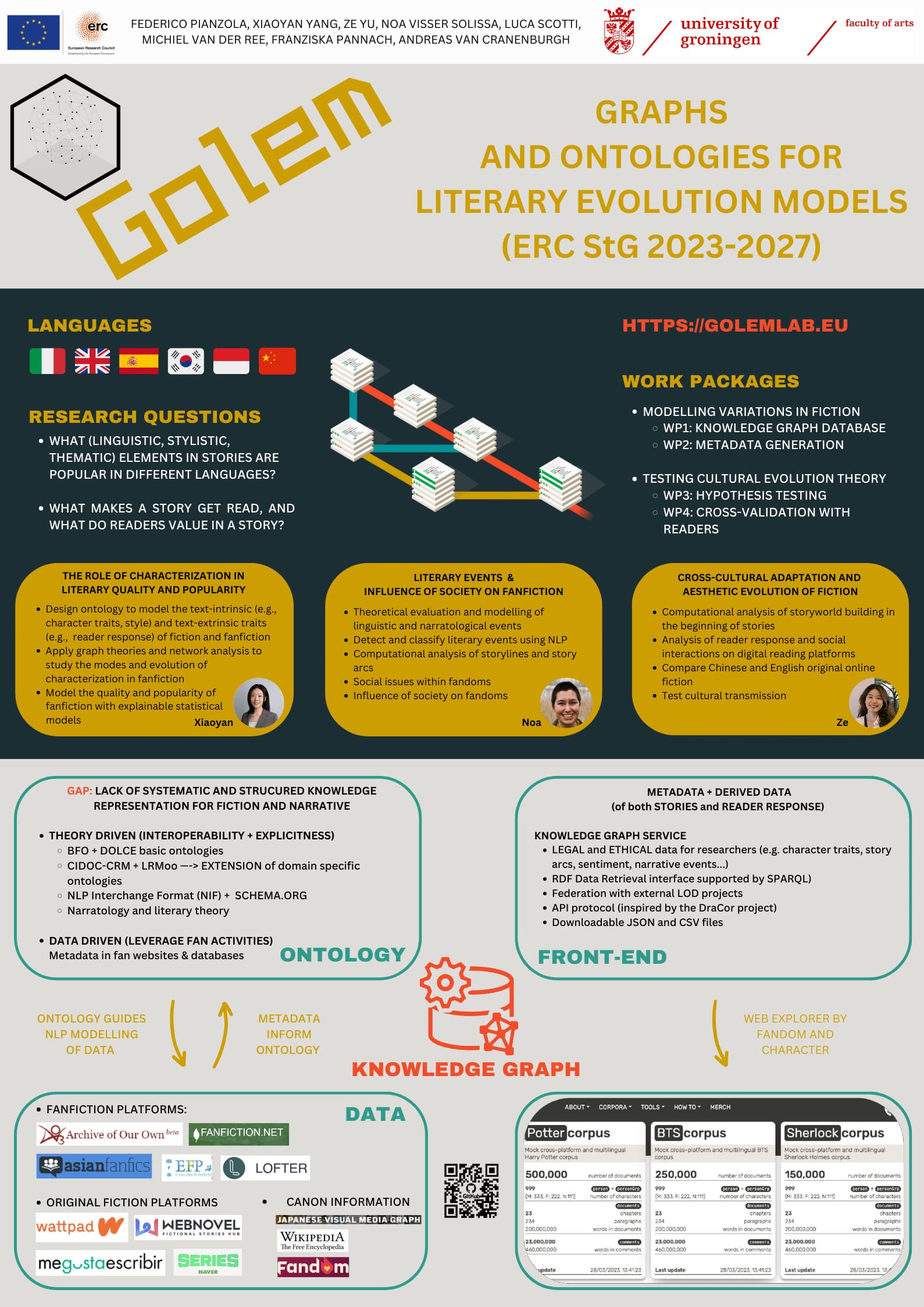
- A Graph Database and an Ontology for Computational Literary Studies (Federico Pianzola, Andreas van Cranenburgh, Xiaoyan Yang, Noa Visser, Michiel van der Ree, Luca Scotti and Ze Yu)
- Telling a Story with Data: shift in the Mediterranean Diet’s discourse from 1950-2020 (Arina Melkozernova, Juliann Vitullo, Ryan Dubnicek, Daniel J. Evans and Boris Capitanu)
- ‘Go into the sea’ or ‘to venture’: Using token embeddings to disentangle lexical usages in Chinese (Jing Chen and Chu-Ren Huang)
- Encoded literary history: A word embedding approach to literary history (Judith Brottrager)
- Profiling charged domains through the lens of correlating subtexts (Ryan Brate and Marieke Van Erp)
- How far back into the past can we trust language phylogenies? (Emma Kopp and Robin Ryder)
- FicTag Visualizer: A Tool for Fanfiction Tag Analysis and Three Use Cases in Fan Interpretation (Julia Neugarten, Christoph Minixhofer and David Slot)
- Investigating the reliability of expert queries in a historical corpus (Thomas Rainsford and Mathilde Regnault)
- Publishing the Neulateinische Wortliste as Linked Open Data (Federica Iurescia, Eleonora Litta, Marco Passarotti and Matteo Pellegrini)
- Explicit References to Societal Values in Fairy Tales: A Comparison between Three European Cultures (Alba Morollon Diaz-Faes, Carla Sofia Ribeiro Murteira and Martin Ruskov)
- How to Evaluate Coreference in Literary Texts? (Ana Duron Tejedor, Pascal Amsili and Thierry Poibeau)
- Understanding the impact of two derived text formats on DistilBERT-based binary sentiment classification (Keli Du and Christof Schöch)
- Словотвiр: a natural experiment in word replacement (Alexey Koshevoy, Olivier Morin and Oleg Sobchuk)
- Dating the Stylistic Turn: the Strength of the Auctorial Signal in Early Modern French Plays (Florian Cafiero and Simon Gabay)
- Computer vision, historical photographs and halftone visual culture (Mohamed Salim Aissi, Marina Giardinetti, Isabelle Bloch, Julien Schuh and Daniel Foliard)
1 Like
Please feel free to post your posters below.